Auto-Numbering in SQL - PostgreSQL
By Mike Hanson
In my opening article, Auto-Numbering in SQL – An Overview, I touched upon many of the issues and decisions that you must tackle to adopt SQL server-side auto-numbering with Clarion. Much of this involved broader concepts, leaving the practical examples for later. In this installment, I'll discuss how this plays out with PostgreSQL.
On the PostgreSQL Server
Each flavor of SQL handles auto-numbering with its own quirks. In the case of PostgreSQL, you'll be dealing with something called a SEQUENCE. There's nothing too mysterious: it's just a counter. It usually starts at 1, and you repeatedly ask it for the next number. The simplest way to create one is:
CREATE SEQUENCE mysequence;
To fetch the next number (and increment the internal counter for the following call), just issue this command:
SELECT nextval('mysequence');If you want to check which number was just assigned, you can use this:
SELECT currval('mysequence');The call to currval must be executed in the same context as the call to nextval, which is the way that we'll be using it.
The SEQUENCE doesn't handle everything. It must be used in conjunction with your TABLE, a primary key constraint, and a primary key field. You also should also tell PostgreSQL that your SEQUENCE is owned by the TABLE, so that dropping the TABLE implicitly tells it to drop the SEQUENCE too.
That sounds like a lot of work, but fortunately there's a way to define all of this in one fairly simple step with a table creation script like this:
CREATE TABLE mytable
(
mytableid serial PRIMARY KEY,
somefield varchar(100)
);
The most important part of this is the definition of mytableid:
- serial isn't a real datatype. It's just a signal to do this:
- use an integer for storage
- create a SEQUENCE called mytable_mytableid_seq
- set the default value for the field as nextval('mytable_mytableid_seq')
- set the sequence attribute of the field to match
- associate the SEQUENCE with the TABLE (so it's dropped if the table is dropped)
- PRIMARY KEY tells it to create a primary key constraint called mytable_pkey with mytableid as the only component
Here are the resulting attributes of mytableid inside pgAdmin:
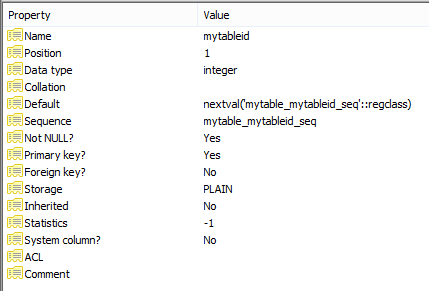
The helpful thing here is that the connection between the field and the sequence provides an more descriptive syntax for retrieving the recently assigned sequence (rather than remembering that it's "tablename_columnname_seq", which could change in the future):
SELECT currval(pg_get_serial_sequence('mytable','mytableid'))The Case of PostgreSQL Labels
You may have noticed that all of the labels I used in PostgreSQL were lowercase. As long as you initially define everything in lowercase, you can mix and match uppercase and lowercase in your scripts later. If, however, you create them with mixed case, then you're going to run into trouble. Just use lowercase and avoid troubles.
Importing Existing Data into PostgreSQL
The auto-numbering is done only as a default value. If you need to transfer existing data into the table, you can do it by specifying the existing values for mytableid in the INSERT statement. It sees the explicit value, so doesn't bother to apply a default. As long as it doesn't request the nextval, then it won't increment the SEQUENCE.
Once you're done importing your data, you can use the ALTER SEQUENCE command to set the counter to the next higher value. For example:
ALTER SEQUENCE mytable_myfield_seq RESTART WITH 1234;
In this case, the next value requested will be 1234 (i.e. your pre-existing values ended with 1233).
In Your Clarion Dictionary
If you're creating an app from scratch, you could import that definition into your dictionary, or you could define it in Clarion from scratch. One thing you don't want to do is let Clarion's CREATE command create the actual table in your SQL database. It will give you rather undesirable results. Instead, use a tool like DMC, FM3 or DCT2SQL, all of which will use a CREATE TABLE script on the server side.
For the sake of this article, I imported the definition from PostgreSQL into the dictionary.
PostgreSQL labels are lowercase, but most of us don't want to use lowercase labels inside Clarion. Fortunately, you can use set the External Names within the dictionary, so that Clarion always talks to PostgreSQL with lowercase names, but lets you see your labels inside Clarion as MixedCase.
To get the auto-numbering to work, you have to visit three main areas: the auto-numbered field, the primary key, and the file definition.
Auto-Numbered Field
In the SQL table creation script above, the field name is mytableid. You can adjust that, and tell it a bit more about its auto-numbering duty:
- Change the Label to the mixed case MyTableID.
- Note the Data Type should be LONG.
- On the Attributes tab, set the External Name to mytableid | READONLY.
- The first part is the lowercase name of the column in your PostgreSQL table.
- READONLY tells Clarion that the field will always be set in the back-end, so never attempt to assign values to it directly. Note the space on either side of the pipe character is required!
- On the Options tab, add a new property IsIdentity. It's a Boolean, with a value of TRUE.
If you are using FM3, you can add the ForceSQLDataType Option and set it to serial, so that FM3 automatically uses this type when it creates your SQL table. I've not had a chance to experiment with this myself, and I'll report back here if I run into problems with it.
Primary Key
You may have learned that keys defined on the Clarion side are there primarily for template use, and they need not be defined as-is on the SQL side. Clarion will use the key definition in the dictionary to build the ORDER BY clause sent to SQL. Keys on the SQL side are for efficient queries, and need not be the same in Clarion. In summary, the keys defined in Clarion don't have to be defined in SQL, and vice versa.
The primary key is an exception to this. It's critical that you define a primary key on the Clarion side that matches the basic structure of the primary key on the SQL side. It need not be given the same name (although it doesn't hurt). It's critical, though, that it contain the same fields/columns, and be marked as PRIMARY on both sides. (On the SQL side it's actually called a "Constraint".)
For the sake of my example dictionary, the primary key's Label will be PK_MyTable. Just for consistency, I set the External Name to match the label on the PostgreSQL side, mtable_pkey. Note that it won't be used in any query statement to the back end. In addition, check the following settings for the key:
- Require Unique Value is ON
- Primary Key is ON
- Auto-Number is OFF (That's right!)
- Exclude Empty Keys is OFF
- Case Sensitive is ON
- The single Column within the key is MyTableID
Table
Although they aren't all related to auto-numbering, I'll describe most of the Table settings, to help clarify ongoing confusion:
- I usually make the Table's Prefix match its Label, so that Customer:Name and Customer.Name are more easily recognized as the same thing. The prefix size is limited, though, so sometimes you're forced to abbreviate it.
- The Driver is ODBC. (There is no native driver for PostgreSQL.)
- The Driver Options need an /AUTOINC attribute. This specifies the SQL command that's executed after the INSERT statement, to determine the new sequence value that was just assigned. Note the punctuation, which is not clear the official Clarion docs. If you happen to use Clarion's dialog in the dictionary editor, it will punctuate it like the second example (and get really weird looking in your generated source). Both work.
/AUTOINC=SELECT currval(pg_get_serial_sequence('mytable','mytableid'))
/AUTOINC='SELECT currval(pg_get_serial_sequence(''mytable'',''mytableid''))'- There are several additional driver options that you can add. They don't specifically related to auto-numbering, but you should add them nonetheless. You can look up each of these in the Clarion help:
/BUSYHANDLING=2 /NESTING=1 /USEDECLAREFETCH=1
- The Owner Name contains the SQL Connection String. In my example I hard coded it, but usually I use a global variable that's used for all tables. The value is set once when the program begins. Although Clarion doesn't currently support Unicode, it's recommended that you use the Unicode driver. (If you're using UTF-8 encoding, then most of the western character set is the same as with ANSI.) The curly braces can be omitted. The server in this case is called closet (which is also its address), the default port for PostgreSQL is 5432, the database is called test, the user is usr, and the password is pwd:
Driver={PostgreSQL UNICODE};Server=closet;Port=5432;Database=test;Uid=usr;Pwd=pwd;- The Full Path Name is public.mytable. Note that as with the sequence name above, it's all lowercase, and I specify the Schema. In PostgreSQL the default is schema is public, compared to Microsoft SQL Server where it's dbo.
- The Create attribute is OFF. (You don't want Clarion to create the table on your SQL back end.)
Conclusion
As you can see, there are many crucial steps to get this to work – much more complicated than relative simplicity of Clarion's "Auto Number" attribute on its keys. If you miss one piece, it's not going to work. You're probably asking why it needs to be this complicated, and the answer is the age old conundrum of flexibility breeding complexity.
When Clarion controls everything (including the data in a DAT or TPS file), then it can provide a simple approach. Once you move to SQL, it's recommended that you do things they way they do, and each flavor of SQL is a little different. Clarion provides all the pieces to make this work, but it's certainly harder overall. SQL makes up for it with speed, robustness, and flexibility, as well as no more TPS corruptions, etc. It's a trade-off, and overall SQL is worth the trouble.
3rd-party tools like DMC, FM3 and DCT2SQL help to simplify your job, and you can turn to consulting firms like Mitten to help with your conversion. Even so, life with SQL is definitely more complicated than good old TPS or DAT files (with all of their warts).