SQLite: The Dummy Table Technique
- David Harms
by Unknown user
When last heard from, your intrepid author (c'est moi) concluded that SQLite was not a lightweight replacement for SQL. I reached this conclusion because I had tried The Dummy Table Technique (see Getting Useful Information out of SQL, Part 2, at Clarion Mag, for a complete description of this technique), in fact a number of variations on it, to get totals from a SQLite file:
Dummy FILE,DRIVER('SQLite'),OWNER(GLO:dbName),PRE(DUM),BINDABLE,THREAD
Record RECORD,PRE()
Field1 CString(256)
END
End
Then, if I want a count of total articles in the ARTICLES table:
Open(Dummy)
dummy{Prop:SQL} = 'select count(*) as total from articles;'
Next(Dummy)
TotalArticles = DUM:Field1
Close(Dummy)
TotalArticles should contain the number I want.
It didn't. In fact, I got run time errors. Every method I tried gave me a File Not Found error (ErrorCode 2). I just couldn't get it to work and stopped trying.
Using a VIEW
An alternative method to get the kind of totals I am after comes to us from Geoff Bomford. Geoff recommends using a Clarion VIEW:
MyView VIEW(AnyTable)
PROJECT(AT:ALong)
END
OPEN(MyView)
MYView{Prop:SQL} = <SQL statement>
Next(MyView)
! AT:Long now has your returned value
CLOSE(MyView)
Suppose I create a local VIEW on the ARTICLES table:
MyView View(Articles) ! Using existing file
Project(ART:ArticleID)
End
then
Open(MyView)
MyView{Prop:SQL} = 'Select count(*) from articles;'
Next(MyView)
x# = ART:ArticleID
Close(MyView)
stop(x#)
worked, returning the correct count. Other queries (for total published articles and unpublished articles) also worked quite nicely.
Three queries took 0 ticks on a 400 record file. The previous totaling checked RECORD(ARTICLES), LOOPed through ARTICLES to count articles not yet published then subtracted to get a “published count.” The TPS code took 3 ticks. Not a significant difference but what if there were 40000 records?
However, there is something more than a little strange about creating a VIEW on the primary file of the Browse procedure. If I were using this code to dynamically update totals, after returning from an update form (an alternative to Clarion's built in totaling, which will get slower as record count grows), I suspect using the primary file's fields would have unexpected and undesirable results. In any case, I really do not want to find out.
If I base the VIEW on the DUMMY table, in essence combining The Dummy Table Technique with the VIEW technique:
MyView View(Dummy) ! Using dummy file
Project(DUM:Field1)
End
I get the same errors I did when using just The Dummy Table Technique or just the VIEW technique.
This Gives Me an Idea!
The problem, in both scenarios, seems to be that SQLite expects the DUMMY table to actually exist. Physically. Contrary to the way The Dummy Table Technique is supposed to work.
But why not allow my application to create it? A good question.
CREATEing the file seems safe to me, after thinking about it – even though it runs against my preference not to unnecessarily multiply entities – for one very good reason. There is no I/O performed against DUMMY. Therefore, while DUMMY would physically exist, it will always be empty.
The Dummy Table Technique needs the file BUFFER, not the physical file. SQLite, in its flat-file mode, requires the physical file. But all my application actually uses is the BUFFER.
So, let the application CREATE the file (by placing it in the table schematic):

Figure 1: Let the app create the file
Using a VIEW on the DUMMY table has one salutary effect. In the standard Dummy Table Technique, fields in the dummy table are filled in the order results are returned by the query. That means that the typical dummy has to be populated with STRINGs or CSTRINGs exclusively. Because I don't really know what data types I'll be requesting in my application, I have to provide fields that can handle anything – relying on Clarion's automatic data type conversion – that might be returned.
Using a VIEW, I can pick and choose the file fields that are PROJECTed, i.e., which fields and in what order, thus controlling the data characteristics the query can access.
So, I can create a DUMMY table containing one (or more) of any data type I want:
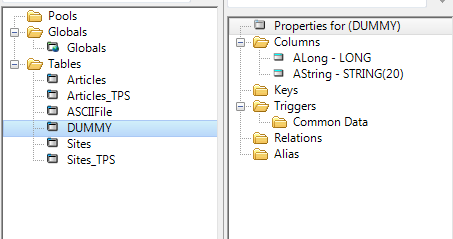
Figure 2: DUMMY table DCT spec
If I want counts, I want a LONG, so I PROJECT only the LONG:
MyView View(DUMMY) ! using dummy file, file must be in DCT
Project(DUM:ALong) ! and must "exist"
End
And I can return the query directly into the correct data type:
Open(MyView)
MyView{Prop:SQL} = 'Select count(*) from articles where ' & |
DatePosted <> "0000-00-00" and DatePosted <= "' & |
sc.SQLiteDateFromClarion(Today()) & '";' ! published
Next(MyView)
LOC:Published = DUM:ALong
Close(MyView)
stop('total ' & LOC:Published)
Conclusion
Combining The Dummy Table Technique and the VIEW technique seems, at first, inelegant. Perhaps this perception is due to the need for the table to physically exist. Perhaps this perception is due to having wrapped my head around the peculiarities of The Dummy Table Technique and now having to deal with a new peculiarity. But it works. Real SQL queries are available with the known features of SQLite.
But, because I can declare and CREATE a VIEW locally, the data types and the data layout (field order) can be customized to the exact needs of the procedure's query. There's something to be said for that.